Introduction
The result of the data science process is to communicate findings, typically to an audience that doesn’t talk technical. It is the most important deliverable of the process, even if not the first thing that springs to mind when considering data science. Fantastic insights are of no use if the intended audience doesn’t understand or trust it. It is therefore vital to take care when presenting findings.
There are typical and often repeated actions when summarising data in tables. It adds overhead to transform analysis specifically to create presentation-ready results. I have developed an approach and associated functions that streamline these tasks, with the benefit of making presentation consistent.
The following scenarios are addressed:
Scenarios when summarising tables
Boolean Features
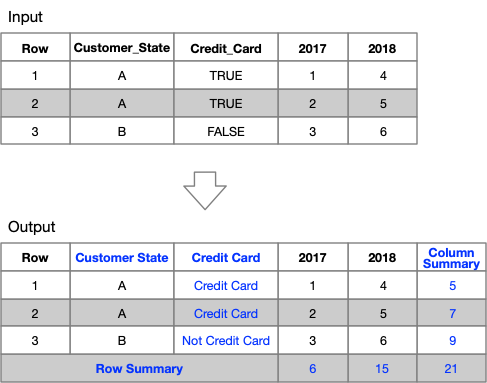
I often create and usebooleanfeatures as it makes analysis consistent and easier to follow, especially when used asfilterconditions.
However, it is difficult to review summary tables when labels readTRUEorFALSE, especially when multiple boolean features are presented. Replacing it with descriptive labels improves legibility.
See Credit Card example shown above.
The functionfunc_legible_booleanin the code block below achieves this.Table Summaries
By row or column, either summarising mulitple columns into one, or the content of each selected column. Summaries are often a sum total of numeric fields, but can be other summary statistics too.
The functionfunc_create_summarycreates a row summary.Headers
Remember the days when you had to dial a phone number when making a call? 😄
It is a lot easier to code when features have no spaces, specifically using the autocomplete feature of code editors. I therefore use underscores as placeholders.
It is a good idea though to revert the underscores to spaces when presenting tables.func_present_headerstakes care of this.
Code
Library
Load the packages used in the demonstration.
package_list <- c("tidyverse", "lubridate", "knitr")
invisible(suppressPackageStartupMessages(lapply(package_list, library, character.only = TRUE)))
rm(package_list)
options(digits=9)Functions
The functions instantiated in following code block addresses the scenarios listed above. The inline comments below describe the working and sequence of each function.
func_rename <-
function(x) {
# sequence is important here
# regex removing all chars not alpha-numeric, underscore or period
gsub("[^[:alnum:] \\_\\.]", "", x) %>%
# replace any space or period with underscore
str_replace_all(pattern = " |\\.", replacement = "\\_") %>%
# replace multiple underscores with one
str_replace_all(pattern = "\\_+", replacement = "\\_") %>%
# remove trailing underscores and period
str_remove(pattern = "\\_$|\\.$")
}
func_legible_boolean <-
# returns `feature name` when TRUE and "Not_" + `feature name` otherwise
function(df) {
# only exec if there is a logical field in the df
if (df %>%
select_if(is.logical) %>%
ncol() > 0) {
# add row numbers to input dataframe
df <-
df %>%
ungroup() %>%
mutate(row_id = row_number())
# select row_id and other logical fields
tmp <-
df %>%
select(row_id, select_if(., is.logical) %>% names(.)) %>%
# gather all logical fields and keep row_id to retain identity
gather(key, value,-row_id) %>%
# when value is TRUE then return the feature name else "Not_" pasted in
# front of it
mutate(value = case_when(
value ~ key,
TRUE ~ paste("Not", key, sep = "_")
)) %>%
# return the feature names back to header positions
spread(key, value)
vars <-
df %>%
select_if(is.logical) %>%
names()
df %>%
# return all values from the table after excluding the original logical
# fields and join the newly adjuted features back into the table using the
# row_id
select(-(!!vars)) %>%
inner_join(tmp,
by = "row_id") %>%
# remove the row_id as the join is complete
select(-row_id)
} else {
df %>%
return()
}
}
func_create_summary <-
# group by factors, summarising numeric fields to sum total
function(df) {
# create a list of factors from the input dataframe
tmp_factors <- df %>% select_if(is.factor) %>% names()
# mutate all factors in the dataframe to characters
df <- df %>% ungroup() %>% mutate_if(is.factor, as.character)
# list original dataframe with a newly created summary row
list(
# original input dataframe
df,
# summary row, replaceing each factor value to "Total"
df %>%
mutate_at(tmp_factors, ~"Total") %>%
# group by for each of the original factor features
group_by_at(tmp_factors) %>%
# summarise all numeric values to sum total, ignoring NULL values
summarise_if(is.numeric, sum, na.rm = TRUE)
) %>%
# union all tables contained in the list, including original dataframe and
# newly created summary row
reduce(union_all) %>%
# change factors back into factors
mutate_at(tmp_factors, factor) %>%
return()
}
func_present_headers <-
function(.) {
# replace all `spaceholder underscores` with spaces
str_replace_all(., pattern = "_", replacement = " ") %>%
# change all words in string to title text
str_to_title() %>%
return()
}Parameters and Configuration
I am using the Brazilian E-Commerce Public Dataset by Olist from kaggle Datasets in this demonstration. The var_path parameter stores the location of the source data within my environment.
var_path <- "~/Documents/Training/datasets/brazilian-ecommerce/"Import
Please note that, parsing in this case, the messages upon readr::read_csv are disabled to make the article more legible.
The code sequence below is written to import a nominated subset of files into a single dataframe (datablock), nesting each file as a tibble.
df_files <-
# traverse the specified directory and add list of files to a table and rename
# the tibble's default column value to file_name_ext, representing the name of
# the file and its extention
list.files(path = var_path,
pattern = ".",
recursive = TRUE) %>%
enframe(name = NULL) %>%
rename(file_name_ext = value) %>%
# remove the file extention to isolate the file name as a separate variable
mutate_at("file_name_ext", list(file_name = str_remove), pattern = "\\.csv") %>%
# build a file path input for each file as used by the file parameter in the
# read_csv function
mutate(file_path = paste0(var_path, file_name_ext)) %>%
# map the file_path to readr::read_csv to iteratively upload each file listed in the
# table
mutate(file = map(file_path, function(param_file_path) {
read_csv(file = param_file_path) %>%
return()
})) %>%
# standardise the naming of each file in situ
mutate_at("file", map, function(df) {
df %>%
rename_all(func_rename) %>%
return()
}) %>%
# remove redundant variables to tidy up the datablock
select(-file_path, -file_name_ext)
# print new table to glance the imported product
df_files## # A tibble: 9 x 2
## file_name file
## <chr> <list>
## 1 olist_customers_dataset <tibble [99,441 × 5]>
## 2 olist_geolocation_dataset <tibble [1,000,163 × 5]>
## 3 olist_order_items_dataset <tibble [112,650 × 6]>
## 4 olist_order_payments_dataset <tibble [103,886 × 5]>
## 5 olist_order_reviews_dataset <tibble [100,000 × 7]>
## 6 olist_orders_dataset <tibble [99,441 × 8]>
## 7 olist_products_dataset <tibble [32,951 × 9]>
## 8 olist_sellers_dataset <tibble [3,095 × 4]>
## 9 product_category_name_translation <tibble [71 × 2]>This confirms 9 files imported, specifying the rows nrow and columns ncol of each nested tibble.
Inspect Data
The function func_inspect_file helps to extract and print the structure of nested tibbles, including olist_order_payments_dataset, olist_orders_dataset and olist_customers_dataset contained within df_files.
Changing the character fields to factors better structures and provides additional information about the features.
func_inspect_file <-
function(param_file_name) {
# create *** separators to pad tibble names followed by printed structure
rep("*", 30) %>% paste(collapse = "") %>% print()
print(param_file_name)
rep("*", 30) %>% paste(collapse = "") %>% print()
df_files %>%
filter(file_name == param_file_name) %>%
select(-file_name) %>%
unnest() %>%
mutate_if(is.character, factor) %>%
head() %>%
str() %>%
print()
}
tibble(
# list tibble names to inspect
param_file = c(
"olist_order_payments_dataset",
"olist_orders_dataset",
"olist_customers_dataset"
)
) %>%
mutate_at("param_file", walk, func_inspect_file)## [1] "******************************"
## [1] "olist_order_payments_dataset"
## [1] "******************************"
## Classes 'tbl_df', 'tbl' and 'data.frame': 6 obs. of 5 variables:
## $ order_id : Factor w/ 99440 levels "00010242fe8c5a6d1ba2dd792cb16214",..: 71446 65633 14657 72396 25967 16046
## $ payment_sequential : num 1 1 1 1 1 1
## $ payment_type : Factor w/ 5 levels "boleto","credit_card",..: 2 2 2 2 2 2
## $ payment_installments: num 8 1 1 8 2 2
## $ payment_value : num 99.3 24.4 65.7 107.8 128.4 ...
## NULL
## [1] "******************************"
## [1] "olist_orders_dataset"
## [1] "******************************"
## Classes 'tbl_df', 'tbl' and 'data.frame': 6 obs. of 8 variables:
## $ order_id : Factor w/ 99441 levels "00010242fe8c5a6d1ba2dd792cb16214",..: 88951 32546 27770 57386 67044 63543
## $ customer_id : Factor w/ 99441 levels "00012a2ce6f8dcda20d059ce98491703",..: 61761 68730 25514 96584 53774 31118
## $ order_status : Factor w/ 8 levels "approved","canceled",..: 4 4 4 4 4 4
## $ order_purchase_timestamp : POSIXct, format: "2017-10-02 10:56:33" "2018-07-24 20:41:37" ...
## $ order_approved_at : POSIXct, format: "2017-10-02 11:07:15" "2018-07-26 03:24:27" ...
## $ order_delivered_carrier_date : POSIXct, format: "2017-10-04 19:55:00" "2018-07-26 14:31:00" ...
## $ order_delivered_customer_date: POSIXct, format: "2017-10-10 21:25:13" "2018-08-07 15:27:45" ...
## $ order_estimated_delivery_date: POSIXct, format: "2017-10-18" "2018-08-13" ...
## NULL
## [1] "******************************"
## [1] "olist_customers_dataset"
## [1] "******************************"
## Classes 'tbl_df', 'tbl' and 'data.frame': 6 obs. of 5 variables:
## $ customer_id : Factor w/ 99441 levels "00012a2ce6f8dcda20d059ce98491703",..: 2611 9562 30461 69606 30708 52562
## $ customer_unique_id : Factor w/ 96096 levels "0000366f3b9a7992bf8c76cfdf3221e2",..: 50397 15434 2273 14193 19734 28806
## $ customer_zip_code_prefix: Factor w/ 14994 levels "01003","01004",..: 4774 3802 68 3586 4307 13965
## $ customer_city : Factor w/ 4119 levels "abadia dos dourados",..: 1383 3429 3598 2342 708 1937
## $ customer_state : Factor w/ 27 levels "AC","AL","AM",..: 26 26 26 26 26 24
## NULL## # A tibble: 3 x 1
## param_file
## <chr>
## 1 olist_order_payments_dataset
## 2 olist_orders_dataset
## 3 olist_customers_datasetJoin
Iterating through a list of tibbles with matching primary and foreign keys will result in a joined dataframe.
Primary and foreign keys on each of the tibbles results in an automatic join for each iteration, using a feature of the dplyr::full_join function to guess joins (column names shared in both tibbles) if none are explicitly provided.
Let’s run the sequence and inspect the head of the resulting datafame.
df_customer_order_payment <-
# a list of tibbles to join
tibble(
param_file = c(
"olist_order_payments_dataset",
"olist_orders_dataset",
"olist_customers_dataset"
)
) %>%
# unnest each tibble listed above, joining it with the result of the previous
# mapping sequence
mutate_at("param_file", map, function(param_file) {
df_files %>%
filter(file_name == param_file) %>%
select(-"file_name") %>%
unnest()
}) %>%
reduce(unnest) %>%
reduce(full_join)## Joining, by = "order_id"## Joining, by = "customer_id"# return head of the joined tibbles
df_customer_order_payment %>%
head() %>%
# specify styling options
kable(format = "html") %>%
kableExtra::kable_styling(full_width = FALSE, font_size = 11) %>%
kableExtra::scroll_box(width = "100%", height = "200px")| order_id | payment_sequential | payment_type | payment_installments | payment_value | customer_id | order_status | order_purchase_timestamp | order_approved_at | order_delivered_carrier_date | order_delivered_customer_date | order_estimated_delivery_date | customer_unique_id | customer_zip_code_prefix | customer_city | customer_state |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| b81ef226f3fe1789b1e8b2acac839d17 | 1 | credit_card | 8 | 99.33 | 0a8556ac6be836b46b3e89920d59291c | delivered | 2018-04-25 22:01:49 | 2018-04-25 22:15:09 | 2018-05-02 15:20:00 | 2018-05-09 17:36:51 | 2018-05-22 | 708ab75d2a007f0564aedd11139c7708 | 39801 | teofilo otoni | MG |
| a9810da82917af2d9aefd1278f1dcfa0 | 1 | credit_card | 1 | 24.39 | f2c7fc58a9de810828715166c672f10a | delivered | 2018-06-26 11:01:38 | 2018-06-26 11:18:58 | 2018-06-28 14:18:00 | 2018-06-29 20:32:09 | 2018-07-16 | a8b9d3a27068454b1c98cc67d4e31e6f | 02422 | sao paulo | SP |
| 25e8ea4e93396b6fa0d3dd708e76c1bd | 1 | credit_card | 1 | 65.71 | 25b14b69de0b6e184ae6fe2755e478f9 | delivered | 2017-12-12 11:19:55 | 2017-12-14 09:52:34 | 2017-12-15 20:13:22 | 2017-12-18 17:24:41 | 2018-01-04 | 6f70c0b2f7552832ba46eb57b1c5651e | 02652 | sao paulo | SP |
| ba78997921bbcdc1373bb41e913ab953 | 1 | credit_card | 8 | 107.78 | 7a5d8efaaa1081f800628c30d2b0728f | delivered | 2017-12-06 12:04:06 | 2017-12-06 12:13:20 | 2017-12-07 20:28:28 | 2017-12-21 01:35:51 | 2018-01-04 | 87695ed086ebd36f20404c82d20fca87 | 36060 | juiz de fora | MG |
| 42fdf880ba16b47b59251dd489d4441a | 1 | credit_card | 2 | 128.45 | 15fd6fb8f8312dbb4674e4518d6fa3b3 | delivered | 2018-05-21 13:59:17 | 2018-05-21 16:14:41 | 2018-05-22 11:46:00 | 2018-06-01 21:44:53 | 2018-06-13 | 4291db0da71914754618cd789aebcd56 | 18570 | conchas | SP |
| 298fcdf1f73eb413e4d26d01b25bc1cd | 1 | credit_card | 2 | 96.12 | a24e6f72471e9dbafcb292bc318f4859 | delivered | 2018-05-07 13:20:41 | 2018-05-07 15:31:14 | 2018-05-10 13:35:00 | 2018-05-14 19:02:54 | 2018-05-23 | 6e3c218d5f0434ddc4af3d6a60767bbf | 13614 | leme | SP |
The head of the dataframe confirms the result of the join.
Results
Grouping Parameter
The configurable param_vars_grouping parameter is populated with variables to be used to group the content of the df_customer_order_payment dataframe.
param_vars_grouping <- vars(customer_state, Purchase_year, Credit_Card)Output
This is where we implement the functions previously described to create a presentation-ready summary table of the payment data contained in the df_customer_order_payment dataframe.
df_customer_order_payment_data <-
df_customer_order_payment %>%
# create a new boolean feature Credit_Card, defaulting all NULL values to
# FALSE and make it `legible` using the func_legible_boolean function
mutate(Credit_Card = coalesce(payment_type == "credit_card", FALSE)) %>%
func_legible_boolean() %>%
# simplify the order_purchase_timestamp to keep year only and store in a newly
# created `Purchase_year` feature
mutate_at("order_purchase_timestamp", list(Purchase_year = year)) %>%
# change all grouping variables to factor, grouping by all factors and
# summarising payment_value for each combination of grouping variables
mutate_at(param_vars_grouping, factor) %>%
group_by_if(is.factor) %>%
summarise_at("payment_value", sum, na.rm = TRUE) %>%
ungroup() %>%
# keep the top 3 customer_states ordered by desc payment_value total and lump
# the other states into `Other`
mutate(customer_state = fct_lump(f = customer_state, w = payment_value, n = 3)) %>%
# regroup all factors based on the revised customer_state, and recalculate the
# sum total for combinations
group_by_if(is.factor) %>%
summarise_if(is.numeric, sum, na.rm = TRUE) %>%
# spread the payment values for each grouping combination by year
spread(Purchase_year, payment_value) %>%
ungroup() %>%
# regroup and nest the summary content for each grouping combination
group_by_if(is.factor) %>%
nest() %>%
# map each nested summary, gather the values and elongate the summary, summing
# the content of the numeric field only
mutate_at("data", list(total = map), function(df) {
df %>%
gather() %>%
summarise_if(is.numeric, sum, na.rm = TRUE) %>%
# rename to Total as it will be added back into the grouping tibble when
# unnested
rename(Total = value) %>%
# return the result
return()
}) %>%
# unnest the newly created 'Total' feature
unnest()
df_customer_order_payment_data %>%
# summarise each numeric column into sum totals
func_create_summary() %>%
# rename all headers by replacing placeholder underscores with spaces
rename_all(func_present_headers) %>%
# round all numeric values up to the nearest dollar and format value as
# currency
mutate_if(is.numeric, ~round(.) %>% scales::dollar(.)) %>%
mutate_if(is.character, str_remove, pattern = "\\$NA") %>%
# rename all factor values by replacing placeholder underscores with spaces
mutate_if(is.factor, str_replace_all, pattern = "_", replacement = " ") %>%
# align tabular values right and output as html
kable(align = "r", format = "html") %>%
kableExtra::kable_styling(full_width = FALSE,
font_size = 12) %>%
# merge duplicate rows into single cells (matplotlib style) to improve clarity
kableExtra::collapse_rows(columns = 1,
valign = "top") %>%
# add additional header categories
kableExtra::add_header_above(c(
"Dimension" = 2,
"Year" = 3,
" " = 1
))| Customer State | Credit Card | 2016 | 2017 | 2018 | Total |
|---|---|---|---|---|---|
| MG | Credit Card | $4,832 | $668,567 | $798,576 | $1,471,975 |
| Not Credit Card | $811 | $186,324 | $213,146 | $400,282 | |
| RJ | Credit Card | $10,137 | $849,698 | $870,506 | $1,730,341 |
| Not Credit Card | $3,271 | $206,256 | $204,512 | $414,039 | |
| SP | Credit Card | $13,886 | $1,972,256 | $2,690,520 | $4,676,662 |
| Not Credit Card | $2,999 | $589,607 | $728,958 | $1,321,565 | |
| Other | Credit Card | $19,708 | $2,146,853 | $2,496,545 | $4,663,106 |
| Not Credit Card | $3,718 | $630,185 | $696,999 | $1,330,902 | |
| Total | Total | $59,362 | $7,249,747 | $8,699,763 | $16,008,872 |
Another approach to output
This following section is a stylised alternative to the previous, creating separate summary tables for the boolean Credit Card payments options. The intention, in line with the theme of this article, is to improve clarity by breaking data into smaller, bite-size chunks.
The approach is instantiating the func_output_group_item_table function that takes as input a grouping parameter, and output the filtered results for distinct and consecutive categories within it.
func_output_group_item_table <-
function(param_group, param_group_selector) {
# print the distinct grouping category as header
cat(paste0(
"<h4>",
str_replace_all(param_group, pattern = "_", replacement = " "),
"</h4>"
))
df_customer_order_payment_data %>%
# filter the master data by the grouping category parameter
filter(!!param_group_selector == param_group) %>%
ungroup() %>%
# remove the grouping category from it
select(-!!param_group_selector) %>%
# create a row with a sum total for each numeric column
func_create_summary() %>%
# styling and presentation options executed next, as described in the
# previous code block
rename_all(func_present_headers) %>%
mutate_if(is.numeric, ~ round(.) %>% scales::dollar(.)) %>%
mutate_if(is.character, str_remove, pattern = "\\$NA") %>%
mutate_if(is.factor,
str_replace_all,
pattern = "_",
replacement = " ") %>%
kable(align = "r", format = "html") %>%
kableExtra::kable_styling(full_width = FALSE,
font_size = 12) %>%
kableExtra::collapse_rows(columns = 1:4, valign = "middle") %>%
return()
}
func_output_group_item_table_iterator <-
function(param_group_selector) {
for (param_group in (df_customer_order_payment_data %>%
distinct(!!param_group_selector) %>%
pull())) {
func_output_group_item_table(param_group, param_group_selector) %>% print()
}
}By Credit Card
# input the grouping parameter to output sectioned item tables
func_output_group_item_table_iterator(quo(Credit_Card))Credit Card
| Customer State | 2016 | 2017 | 2018 | Total |
|---|---|---|---|---|
| MG | $4,832 | $668,567 | $798,576 | $1,471,975 |
| RJ | $10,137 | $849,698 | $870,506 | $1,730,341 |
| SP | $13,886 | $1,972,256 | $2,690,520 | $4,676,662 |
| Other | $19,708 | $2,146,853 | $2,496,545 | $4,663,106 |
| Total | $48,562 | $5,637,374 | $6,856,148 | $12,542,084 |
Not Credit Card
| Customer State | 2016 | 2017 | 2018 | Total |
|---|---|---|---|---|
| MG | $811 | $186,324 | $213,146 | $400,282 |
| RJ | $3,271 | $206,256 | $204,512 | $414,039 |
| SP | $2,999 | $589,607 | $728,958 | $1,321,565 |
| Other | $3,718 | $630,185 | $696,999 | $1,330,902 |
| Total | $10,800 | $1,612,373 | $1,843,615 | $3,466,788 |
By Customer State
# input the grouping parameter to output sectioned item tables
func_output_group_item_table_iterator(quo(customer_state))MG
| Credit Card | 2016 | 2017 | 2018 | Total |
|---|---|---|---|---|
| Credit Card | $4,832 | $668,567 | $798,576 | $1,471,975 |
| Not Credit Card | $811 | $186,324 | $213,146 | $400,282 |
| Total | $5,643 | $854,892 | $1,011,723 | $1,872,257 |
RJ
| Credit Card | 2016 | 2017 | 2018 | Total |
|---|---|---|---|---|
| Credit Card | $10,137 | $849,698 | $870,506 | $1,730,341 |
| Not Credit Card | $3,271 | $206,256 | $204,512 | $414,039 |
| Total | $13,408 | $1,055,954 | $1,075,018 | $2,144,380 |
SP
| Credit Card | 2016 | 2017 | 2018 | Total |
|---|---|---|---|---|
| Credit Card | $13,886 | $1,972,256 | $2,690,520 | $4,676,662 |
| Not Credit Card | $2,999 | $589,607 | $728,958 | $1,321,565 |
| Total | $16,886 | $2,561,863 | $3,419,479 | $5,998,227 |
Other
| Credit Card | 2016 | 2017 | 2018 | Total |
|---|---|---|---|---|
| Credit Card | $19,708 | $2,146,853 | $2,496,545 | $4,663,106 |
| Not Credit Card | $3,718 | $630,185 | $696,999 | $1,330,902 |
| Total | $23,426 | $2,777,038 | $3,193,544 | $5,994,008 |
Summary
The demonstrated functions are invaluable in my workflow, without which the result would not be as effective nor consistent.
The functions are continuously evolving, becoming more configurable and robust while keeping the emphasis on simplicity and ease-of-use.
It shaves a lot of time off repetitive preparation and keeps me focused on the problem without the distraction of presentation.
Join the discussion below and add your tips and tricks when preparing to communicate results.
Session
sessionInfo()## R version 3.5.3 (2019-03-11)
## Platform: x86_64-apple-darwin15.6.0 (64-bit)
## Running under: macOS Mojave 10.14.4
##
## Matrix products: default
## BLAS: /Library/Frameworks/R.framework/Versions/3.5/Resources/lib/libRblas.0.dylib
## LAPACK: /Library/Frameworks/R.framework/Versions/3.5/Resources/lib/libRlapack.dylib
##
## locale:
## [1] en_GB.UTF-8/en_GB.UTF-8/en_GB.UTF-8/C/en_GB.UTF-8/en_GB.UTF-8
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] knitr_1.22 lubridate_1.7.4 forcats_0.4.0 stringr_1.4.0
## [5] dplyr_0.8.0.1 purrr_0.3.2 readr_1.3.1 tidyr_0.8.3
## [9] tibble_2.1.1 ggplot2_3.1.1 tidyverse_1.2.1
##
## loaded via a namespace (and not attached):
## [1] tidyselect_0.2.5 xfun_0.6 haven_2.1.0
## [4] lattice_0.20-38 colorspace_1.4-1 generics_0.0.2
## [7] viridisLite_0.3.0 htmltools_0.3.6 emo_0.0.0.9000
## [10] yaml_2.2.0 utf8_1.1.4 rlang_0.3.4
## [13] pillar_1.3.1 glue_1.3.1 withr_2.1.2.9000
## [16] selectr_0.4-1 modelr_0.1.4 readxl_1.3.1
## [19] plyr_1.8.4 munsell_0.5.0 blogdown_0.12
## [22] gtable_0.3.0 cellranger_1.1.0 rvest_0.3.3
## [25] kableExtra_1.1.0 evaluate_0.13 fansi_0.4.0
## [28] highr_0.8 broom_0.5.2 Rcpp_1.0.1.2
## [31] scales_1.0.0 backports_1.1.4 webshot_0.5.1
## [34] jsonlite_1.6 hms_0.4.2 digest_0.6.18
## [37] stringi_1.4.3 bookdown_0.9 grid_3.5.3
## [40] cli_1.1.0 tools_3.5.3 magrittr_1.5
## [43] lazyeval_0.2.2 crayon_1.3.4 pkgconfig_2.0.2
## [46] xml2_1.2.0 assertthat_0.2.1 rmarkdown_1.12
## [49] httr_1.4.0 rstudioapi_0.10 R6_2.4.0
## [52] nlme_3.1-139 compiler_3.5.3